

Open Loyalty is the #1 headless API-driven loyalty system that allows companies to launch loyalty campaigns they need and manage them at scale.
You can integrate the platform with any customer-facing application including eCommerce, mobile apps, digital e-kiosks, and others. It helps to create a unique and personalized user experience at each of the channels. Open Loyalty also includes an admin panel built for marketers to easily access customer information, lunch target campaigns, and manage rewards without any tech support.
Open Loyalty can help you execute your loyalty program strategy fast, customize it to your needs, and make it grow together with your business.
The system allows you to pick the features you are interested in, and we create a complete solution for you. Thanks to components and headless approach, every loyalty program based on Open Loyalty is unique and perfectly synchronized with your business.
Leading Australian insurance company
They needed a tailor-made loyalty engine that could be quickly implemented on their on-premise servers for data protection. We managed to build a dedicated loyalty system customized for the client’s needs in just three months. The scope of the project was extended, and we continue our collaboration ever since.
US-based major fuel brand
They wanted to update their system engine. The company needed a strong, robust base to make sure they could create modern solutions that would keep up with the evolving market. Open Loyalty caught their eye because it has all the needed features and could be customized to meet their requirements.
Check out how Open Loyalty looks on the inside!
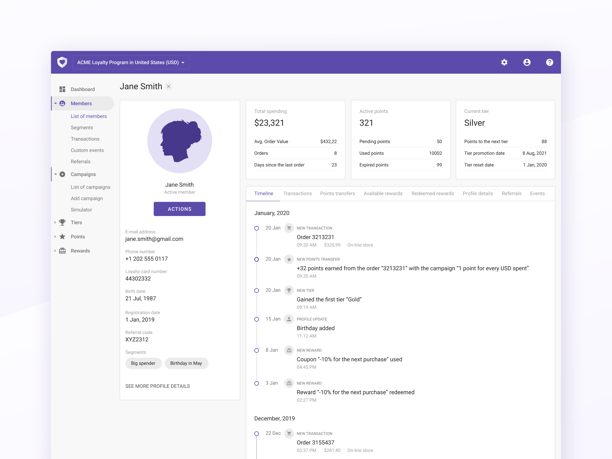
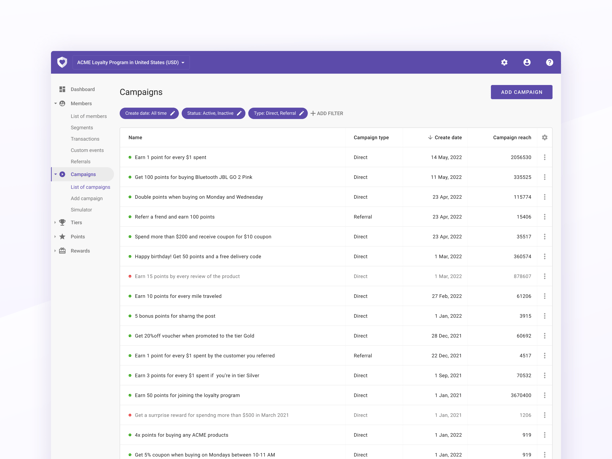
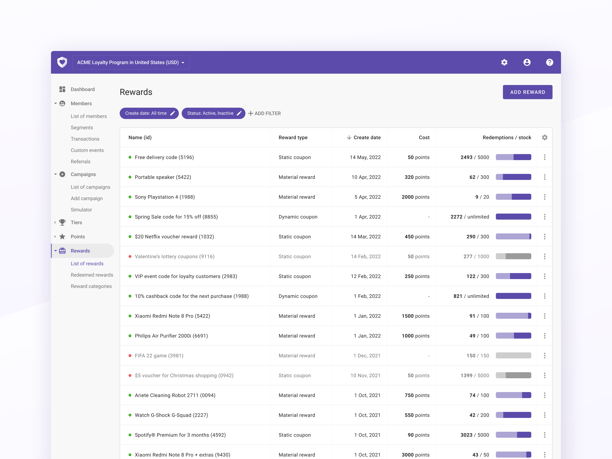
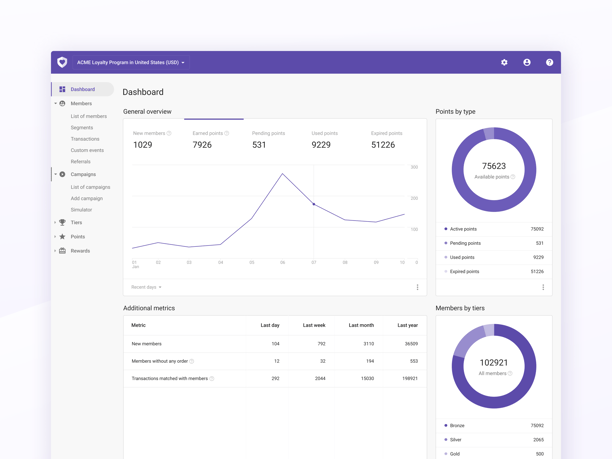
Open Loyalty is definitely different from other loyalty solutions. This headless, API-first system is highly scalable, flexible, and functional. Here are the main benefits your company can get by choosing Open Loyalty over other providers:
On-premise or cloud-based hosting for the highest level of control, security, and performance.
Customization when it comes to design, functionalities, backend, and other components of the solution.
API-first approach for seamless integrations with external and internal systems like CRM, marketing automation, or POS.
Scalability incomparable to other similar solutions on the market, able to handle millions of users.
Support for running loyalty programs in all kinds of touchpoints like mobile applications, eCommerce, POS, e-kiosks, chatbots, and much more.
The curated process to offer quick time-to-market, optimized cost, and insight into every stage of collaboration.
Maintenance services and the know-how to help you quickly learn how to operate with your new loyalty program.





Benefits of Open Loyalty
.svg)
Product trusted by big players
Quick to implement, flexible, and scalable are the unique traits of OL that make it the #1 loyalty provider on the market. Enterprises that work with thousands of clients daily trust Open Loyalty, because it’s a robust solution that can handle complex programs.
.svg)
MACH architecture for customization
Headless, API-first architecture means you can create various loyalty programs based on your business goals and customers’ needs. Every part can be in-tune with your business in terms of design and communication. You get full control over every aspect of loyalty.
.svg)
Faster and cheaper than building from scratch
Building loyalty platforms from scratch can be complicated and time-consuming because it's software with complex logic. Bet on trusted solutions tested by other companies to achieve your goals. Open Loyalty integrates with other apps from your tool stack to create your perfect internal work environment.

Why should Divante be your Open Loyalty implementation partner?
You probably wonder why you should work with Divante on your next loyalty program solution and trust Open Loyalty to be its core. Here’s what we can offer:
On the market for over 14 years
Our expertise is broad, as we’ve been collaborating with various clients for so many years. We know each one of them has different needs.
You can count on us when it comes to technological and business recommendations.
Inclusive collaboration
At Divante, the client is our partner that actively participates in the project with their knowledge about the industry, customers, competition, and other details that can be crucial to your loyalty program’s success.
With us, you can be sure you will achieve your goals.
Open Loyalty place of birth
We are the pioneers when it comes to headless loyalty programs. We’ve created a highly adjustable and scalable platform that can be implemented with the individual needs of a particular company in mind.
Thanks to components and customization, every Open Loyalty project is unique and perfectly synchronized with your business.





